











Qu’est-ce que le machine learning ? Tout ce qu’il faut savoir au sujet de l’apprentissage automatique !


Qu’est-ce que le machine learning ? Ce n’est pas une simple question, mais une porte ouverte sur une nouvelle ère technologique qui verra les ordinateurs apprendre par eux-mêmes à partir des données, s’améliorer, et réaliser des tâches toujours plus complexes de façon indépendante.
Cette ère a déjà commencé : l’apprentissage automatique alimente les services de streaming, les feeds des réseaux sociaux, les chatbots, les véhicules autonomes, ou encore les systèmes d’analyse prédictive.
Concrètement, 48 % des entreprises l’emploient déjà d’une façon ou d’une autre (DemandSage).
Plus qu’une avancée technologique, il s’agit d’une manière innovante d’envisager les interactions entre la machine et l’humain, mais aussi entre l’ordinateur et son environnement.
Alors, c’est quoi, précisément, le machine learning ? Voici ce que vous devez savoir sur son fonctionnement et ses applications pratiques.
Qu’est-ce que le machine learning ?
Le machine learning, ou « apprentissage automatique », est une sous-division du domaine de l’intelligence artificielle qui consiste à développer des systèmes capables d’apprendre et de s’améliorer par l’expérience, sans avoir été explicitement programmés pour y parvenir.
Ainsi, les systèmes à base de machine learning sont capables de tirer des informations pertinentes d’ensembles de données utilisés pour leur entraînement (en découvrant des « patterns », des motifs récurrents, dans ces ensembles), afin d’optimiser leurs performances dans l’exécution d’une tâche spécifique.
Souvent utilisés de façon interchangeable, l’intelligence artificielle (IA) et le machine learning (ML) renvoient pourtant à des réalités quelque peu différentes.
L’IA fait référence aux techniques employées pour aider les machines à développer des fonctions cognitives proches de celles du cerveau humain (compréhension, mémorisation, raisonnement, adaptation, communication et apprentissage autonome).
Il s’agit, en somme, de concevoir des modèles capables de raisonner par eux-mêmes.
À l’inverse, on demande « seulement » au machine learning de permettre aux machines d’apprendre de façon autonome, mais sans raisonnement propre, afin de résoudre des problèmes particuliers.
Ce faisant, le ML participe au développement de l’IA (aux côtés d’autres composantes comme le traitement du langage naturel et le deep learning) sans le recouvrir complètement.
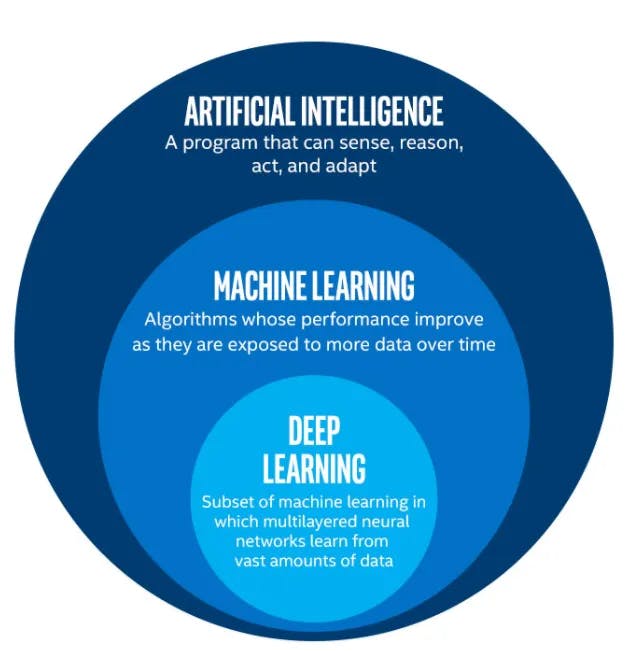
(Source Medium)
Les chiffres du machine learning
Les modèles de machine learning sont entraînés à l’aide d’ensembles de données, puis utilisés pour faire des prédictions sur de nouvelles données (en s’appuyant sur les exemples du passé), et ainsi prendre des décisions plus efficientes.
C’est sans conteste l’une des disciplines les plus en vue dans l’écosystème entrepreneurial technologique : des ingénieurs spécialisés sont recrutés en masse par des groupes comme Amazon, Google, Meta, Microsoft ou Uber. Voici quelques chiffres pour se rendre compte du succès rencontré par cette sous-catégorie de l’IA :
- 100 % des entreprises auront implémenté une forme ou une autre d’intelligence artificielle d’ici 2025 (Forrester).
- 57 % des organisations ont recours au machine learning pour optimiser l’expérience utilisateur ; 49 % s’en servent pour améliorer leurs actions marketing et booster leurs ventes (learn.g2.com).
- 43 % des entreprises adoptent l’IA en raison de ses progrès techniques, 42 % pour automatiser leurs processus et réduire leurs coûts, 37 % pour intégrer le ML dans leurs systèmes et applications. Enfin, 1 entreprise sur 4 se tourne vers l’IA faute de pouvoir recruter ou de pouvoir trouver les compétences nécessaires (IBM Global AI Adoption Index 2022, voir graphique ci-dessous).
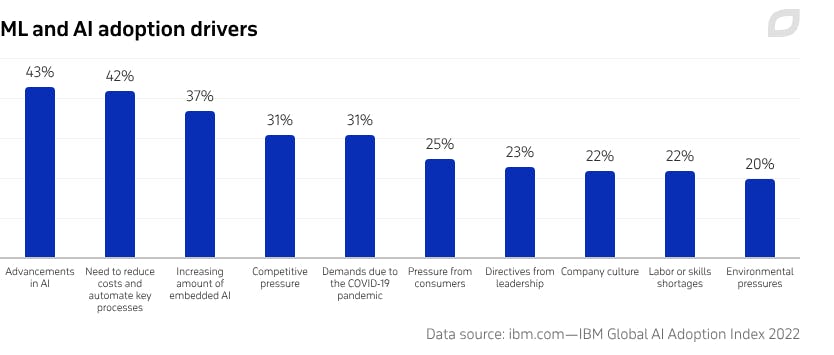
Comment fonctionne le machine learning ?
Voyons plus avant comment fonctionne un modèle de machine learning. La conception d’un tel modèle se déroule en quatre étapes bien délimitées, généralement supervisées par un data scientist.
- La sélection des données d’entraînement qui vont « nourrir » le modèle de ML et lui apprendre à résoudre un problème spécifique (par exemple : faire des recommandations pertinentes aux utilisateurs d’un service de streaming, en fonction de leur historique de visionnage). Ces données sont organisées, nettoyées et structurées avant d’être servies au modèle ; elles peuvent être étiquetées ou non, ou bien en partie seulement, selon l’approche privilégiée (voir plus bas).
- Le choix de l’algorithme à exécuter sur les données d’entraînement. Ce choix se fait sur trois critères : le type de données, le volume de données, et la nature du problème que l’on souhaite résoudre.
- L’entraînement du modèle de ML suivant un processus itératif (la répétition d’une même séquence d’apprentissage). Pour chaque séquence, l’algorithme exécute des variables, puis les résultats sont comparés avec un « modèle » idéal – un peu comme l’on compare un puzzle en cours avec l’image finale que l’on veut reproduire. La séquence est répétée jusqu’à ce que le résultat obtenu corresponde au résultat souhaité dans la plupart des cas, en jouant sur les biais et sur les « poids ». Par exemple, on va entraîner un algorithme à reconnaître un chat sur une photo en utilisant un maximum de points de reconnaissance (la structure du visage, la forme des oreilles, les moustaches…).
- La mise en application du modèle et son amélioration continue. Le modèle de machine learning est confronté à de nouvelles données, elles-mêmes associées au problème à résoudre : il applique alors ce qu’il a appris, et continue de se développer en temps réel. Par exemple, un programme de détection de spams va s’instruire en apprenant à reconnaître de nouvelles adresses d’expédition frauduleuses, et décider seul de bloquer de futurs emails.
Les 4 techniques de machine learning (et leurs algorithmes)
En matière de machine learning, on distingue quatre grandes approches distinctes, qui sont aussi quatre manières différentes d’enseigner au modèle comment identifier des patterns dans des ensembles de données.
Faisons un point sur ces quatre techniques et sur les algorithmes qu’on peut en tirer.
Apprentissage supervisé
C’est l’approche la plus courante : les données sont étiquetées afin d’indiquer à la machine les patterns à identifier, avec un résultat prédéfini.
Elles peuvent aussi être déjà classifiées. Le processus d’entraînement est ainsi facilité, tout comme l’analyse des résultats (ceux-ci étant comparés avec des données étiquetées).
Mais ce modèle est plus enclin à être biaisé, par exemple si les données d’entraînement sont de mauvaise qualité.
Plusieurs algorithmes découlent de l’apprentissage supervisé en machine learning :
- Les algorithmes de régression servent à comprendre les relations qui existent entre les données. La régression linéaire permet de prédire la valeur d’une variable dépendante à partir de la valeur d’une variable indépendante, par exemple : la météo à venir, la croissance de la population ou l’évaluation du risque. La régression logistique est employée en cas de variables dépendantes binaires.
- Les algorithmes de classification servent, comme leur nom l’indique, à classifier des ressources ou des informations, comme des images ou des performances (financières, économiques, commerciales…) à des fins de comparaison.
- Les arbres de décision permettent de faire des recommandations à partir d’un ensemble de règles issues de données classifiées. Ce type d’algorithme de machine learning est employé dans les systèmes de tarification dynamique (sur les marketplaces, notamment) et pour l’analyse prédictive.
Apprentissage non supervisé
Avec l’apprentissage non supervisé, les données ne sont pas étiquetées : la machine explore les ensembles à la recherche de patterns, sans résultat prédéfini (ce qui en revient à recomposer un puzzle sans connaître le modèle initial).
Ce faisant, l’algorithme se charge lui-même d’étiqueter, de trier et de classifier les données, sans guidage humain constant.
Plus difficile à appliquer, cette technique a l’avantage de permettre au modèle de ML de trouver, à l’intérieur d’un ensemble de données, des schémas complexes et des relations que les humains sont incapables d’identifier.
Quelques exemples d’algorithmes :
- Le « clustering » (exemple : la méthode dite des « K-moyennes ») consiste à identifier les groupes qui présentent des enregistrements similaires, et à les étiqueter en fonction de leurs caractéristiques. Ces algorithmes servent au suivi des performances et à la compréhension des intentions des utilisateurs.
- L’algorithme Apriori, ou « d’association », permet de repérer les relations qui existent entre les données. Des règles d’association sont établies à partir des points ou des collections de points les plus fréquents dans un ensemble. Cette approche est employée pour analyser le panier de consommation moyen ou pour faire des recommandations aux utilisateurs (à l’image des suggestions sur les applications de streaming), en évaluant la probabilité qu’un individu ayant consommé un élément X puisse aussi aimer un élément Y.
- Les réseaux de neurones sont composés de plusieurs couches, chacune d’elles ayant son propre rôle : la première ingère les données, la(les) couche(s) cachée(s) en tire(nt) des conclusions (lorsqu’il y en a beaucoup, on parle de « réseau de neurones profond », ou deep learning), et la dernière assigne une probabilité à chacune des conclusions. Ces algorithmes sont utilisés pour la génération de contenu et pour le data mining.
Apprentissage semi-supervisé
Cette approche combine les deux précédentes : des données étiquetées sont employées pour aider la machine à identifier des caractéristiques au sein d’un ensemble plus large de données non étiquetées (cela en revient à recomposer le puzzle avec seulement une toute petite partie du dessin originel accessible).
Une telle technique permet de contourner le problème lorsqu’il existe peu de données étiquetées au moment de l’entraînement, ou lorsque l’accès à un volume suffisant de données s’avère trop coûteux.
Les algorithmes basés sur l’apprentissage semi-supervisé sont surtout employés pour des tâches de classification et de régression.
Apprentissage par renforcement
L’algorithme est autonome : il met tout en œuvre pour atteindre son but, en testant des approches variées et en apprenant de ses erreurs.
À l’issue de chaque tentative, un système de récompense et de pénalité lui indique la voie à suivre ou à abandonner (sachant que l’algorithme est programmé pour obtenir la plus haute récompense possible).
C’est la méthode utilisée pour les algorithmes d’apprentissage de jeux, dont l’application la plus célèbre est AlphaGo, capable de battre un humain au jeu de go.
Les algorithmes les plus connus du machine learning par renforcement sont le TD learning et le Q-learning, deux modèles inspirés des processus humains d’acquisition des connaissances par une succession d’essais et d’erreurs.
L’idée étant d’enseigner aux machines à opérer et à réagir par elles-mêmes.
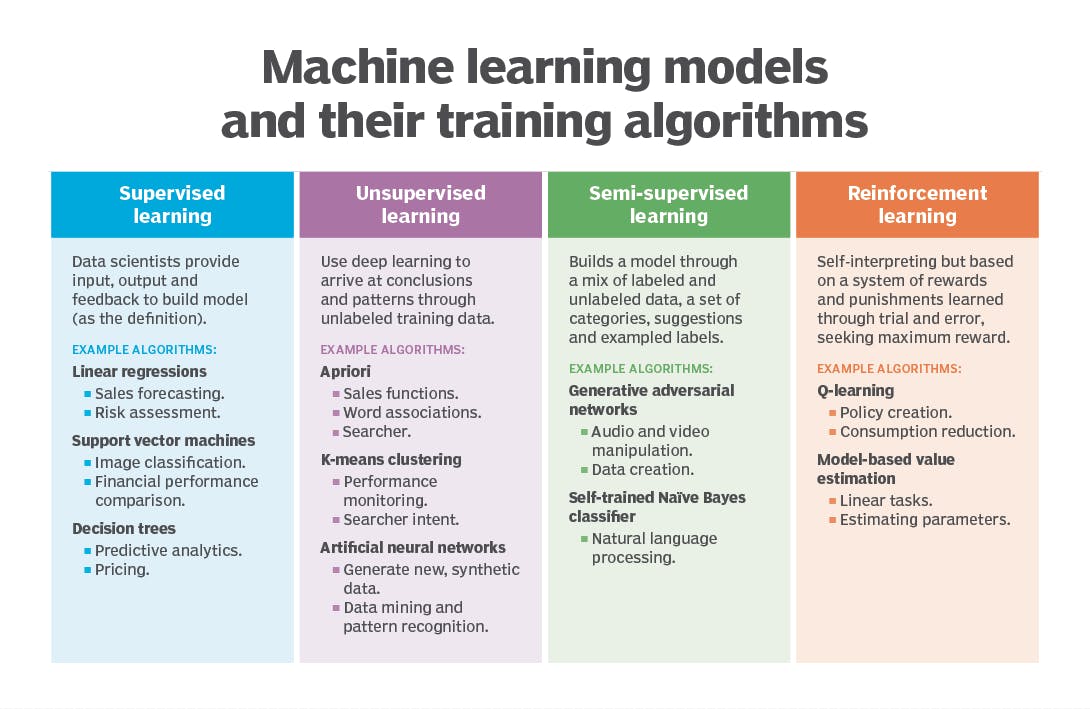
(Source : TechTarget)
Quelles sont les applications du machine learning ?
Au fil de cet article, nous avons répondu à la question « qu’est-ce que le machine learning ? » et expliqué son fonctionnement en substance.
Mais il faut comprendre que beaucoup de services populaires intègrent d’ores et déjà des algorithmes de ML, sans que les utilisateurs en soient nécessairement conscients. C’est pourquoi nous vous proposons un tour d’horizon des applications concrètes du machine learning et des perspectives ouvertes par cette technologie.
- Les mécanismes de recommandation de contenu dans les applications de service : streaming (Spotify, Netflix), partage de vidéos (YouTube), plateformes e-commerce (Amazon), ou encore feeds des réseaux sociaux.
- L’amélioration des diagnostics et des traitements en matière de santé : des outils de machine learning sont utilisés pour aider les personnels médicaux à établir des diagnostics plus pointus et à élaborer des traitements personnalisés, en fonction des besoins spécifiques des patients. En imagerie, l’IA est déjà capable d’identifier des pathologies avec un taux de précision plus élevé que n’importe quel humain.
- L’analyse prédictive sert à définir les grandes tendances à venir dans le comportement des consommateurs, à évaluer les niveaux de risque dans le domaine de l’assurance, ou encore à anticiper les résultats de décisions financières ou politiques.
- La sécurité : des systèmes à base de machine learning sont entraînés à repérer les tentatives de fraude, les arnaques ou bien les interactions abusives (phishing, attaques de l’homme du milieu, etc.). Ce sont ces programmes qui aident les boîtes email à repérer et à catégoriser les spams.
- La mobilité : les véhicules autonomes, encore à l’essai dans plusieurs pays, s’appuient sur des modèles de ML. Mais pas seulement : on utilise également ces modèles pour optimiser les trajets, réduire la consommation de carburant, et améliorer l’efficacité des transports publics.
- Le traitement du langage naturel repose sur des applications de machine learning permettant aux machines de mieux comprendre le langage humain, de l’interpréter, et de générer du contenu en réponse (pour les chatbots, les GPS, les assistants intelligents type Siri ou Alexa, etc.).
- L’industrie : les robots qui exécutent les tâches répétitives et à faible valeur ajoutée dans l’industrie sont alimentés par des algorithmes de machine learning. Dans un avenir proche, ces robots seront employés dans des secteurs de plus en plus diversifiés et pourront prendre en charge des tâches toujours plus complexes.
Le machine learning porte en son sein toutes les promesses faites par la science-fiction d’autrefois : cette technologie nous ouvre la porte d’un monde dans lequel les ordinateurs ne se contentent pas d’exécuter des commandes, mais s’appuient sur de vastes ensembles de données pour prendre des décisions, faire des prédictions, et améliorer leurs performances par leurs propres moyens.
Le fait que les algorithmes de ML se traduisent par des applications transversales, touchant de près ou de loin tous les domaines d’activité, prouve qu’il ne s’agit pas seulement d’une innovation comme une autre, mais d’un levier capable de transformer nos modes de vie.
L’avenir nous dira si cette prédiction (humaine) était juste.
Suivre le podcast
S’abonner au podcast
Recevez mes derniers podcasts directement dans votre boîte mail.