











Grand modèle de langage (LLM) : définition et fonctionnement d’un programme dopé à l’IA !


Autrefois inconnus au bataillon, les grands modèles de langage ont été mis sur le devant de la scène avec le lancement de ChatGPT en 2022.
À cette occasion, le grand public s’est familiarisé avec ces programmes de machine learning capables de saisir les complexités du langage humain et, mieux encore, de générer du texte cohérent en une poignée de secondes, de fournir des réponses pertinentes, et d’extraire des informations exploitables à partir de quantités massives de données.
Mais en coulisses, les large language models existent depuis bien longtemps : les grands noms de la technologie (Google, IBM et autres) développent et entraînent de tels modèles d’IA afin de booster les performances de leurs applications, au profit de l’expérience utilisateur.
Alors, qu’est-ce qu’un grand modèle de langage (LLM) et comment ça fonctionne ?
Qu’est-ce qu’un grand modèle de langage (LLM) ? Une définition
Un grand modèle de langage, ou large language model en anglais (LLM) est un programme d’intelligence artificielle employé pour reconnaître et pour générer du texte.
Pour cela, il utilise une forme d’apprentissage automatique en profondeur (deep learning) basée sur des réseaux neuronaux appelés « transformers ». On parle de « grand modèle » dans la mesure où ce programme est entraîné sur des ensembles massifs de données.
À titre d’exemple, ChatGPT a été alimenté avec une liste de sources publiques et privées contenant plusieurs centaines de millions de documents.
Une fois entraînés, les LLM sont utilisés pour effectuer une multitude de tâches. La mieux connue du grand public est la capacité à répondre à des questions ou des demandes en générant du texte, comme le fait ChatGPT.
Ce dernier peut produire n’importe quel contenu textuel en fonction d’une invite (un « prompt »), qu’il s’agisse d’un article, d’un essai, d’un poème ou d’une synthèse de documentation. Il sait aussi produire du code informatique sur demande.
Néanmoins, de nombreuses autres applications sont possibles : extraction d’informations, analyse des sentiments des utilisateurs, reconnaissance d’images, traduction instantanée, analyse prédictive, détection de fraude, etc.
Autre exemple d’utilisation : de plus en plus, les moteurs de recherche les intègrent à leurs algorithmes pour générer des réponses plus précises aux requêtes des internautes.
Néanmoins, selon la tâche souhaitée, le grand modèle de langage nécessite une phase d’adaptation, afin de se spécialiser dans le domaine voulu (voir plus bas).
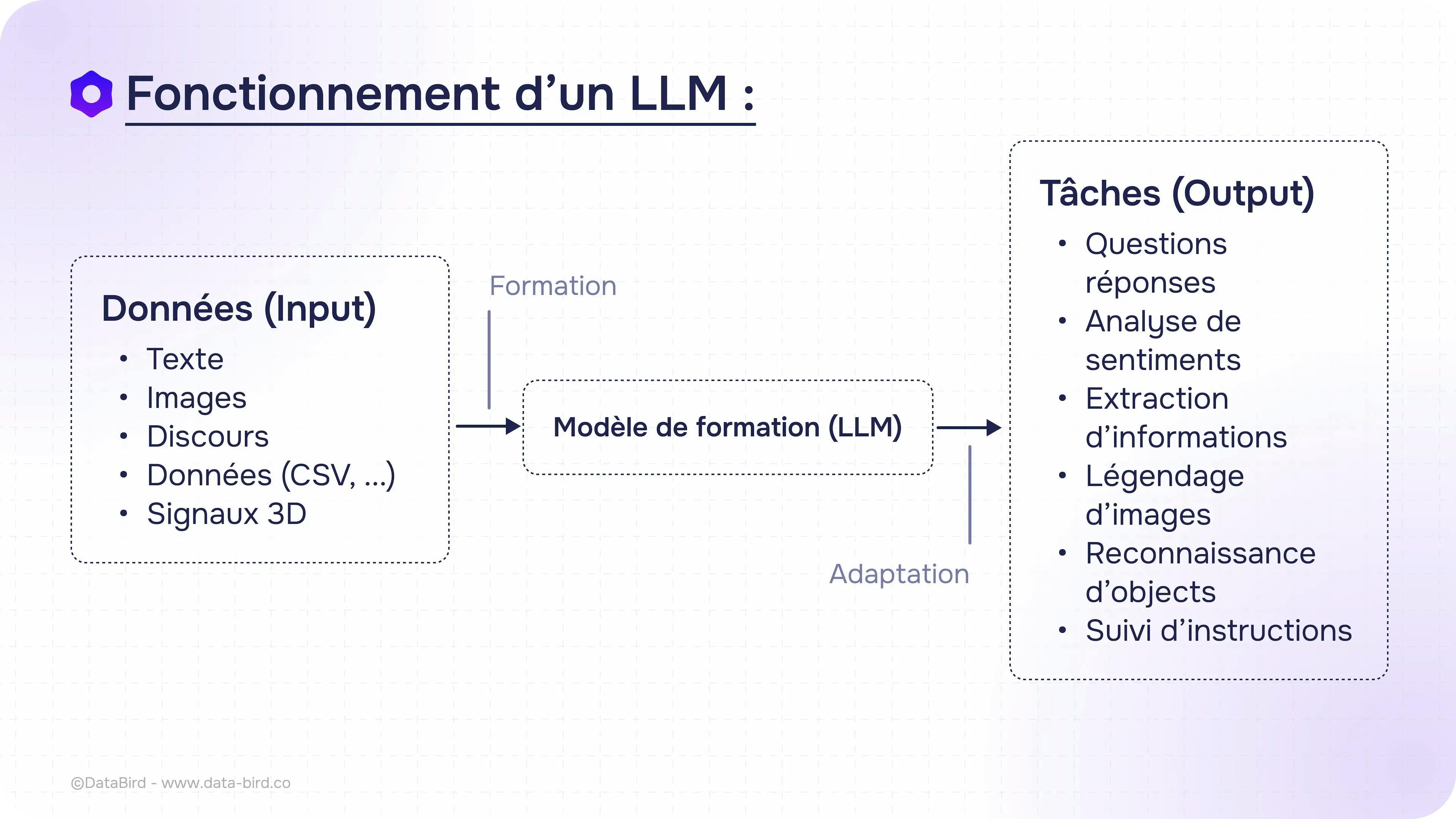
(Source : Data Bird)
Comment fonctionne un grand modèle de langage ?
Le fonctionnement d’un grand modèle de langage repose sur l’apprentissage automatique (machine learning), qui implique une analyse probabiliste des données non structurées, afin d’identifier des éléments de contenu sans intervention humaine.
Deux phases sont indispensables : l’entraînement et le réglage fin.
L’interprétation des éléments et le mécanisme probabiliste
En substance, on fournit au modèle un très grand nombre d’exemples pour lui enseigner à reconnaître des éléments complexes : c’est le processus d’entraînement.
Par la suite, le LLM est capable de reconnaître et d’interpréter ces mêmes éléments dans un tout autre contexte, sans aide extérieure.
Pour expliquer ce processus, on donne souvent l’exemple d’une image de chat : le programme est entraîné à identifier l’animal à partir de nombreux exemples visuels et descriptifs (la forme du visage et des oreilles, les moustaches, la couleur du poil), de façon à pouvoir affirmer avec assurance que la nouvelle image qui lui est soumise est bien celle d’un félin.
L’exemple du chat nous permet aussi de comprendre la fonctionnalité de génération de texte, devenue célèbre avec ChatGPT.
Contrairement à une idée reçue, un grand modèle de langage ne comprend pas le sens des phrases qu’il rédige : il ne fait que prédire le mot suivant dans une séquence donnée, en fonction d’un mécanisme probabiliste.
Le schéma ci-dessous en montre le fonctionnement : lorsqu’on écrit « le chat s’assoit sur le… », le programme évalue la probabilité pour que le terme qui suit immédiatement soit « tapis ».
Il fait cette prédiction en fonction des nombreux exemples qu’il a rencontrés durant son entraînement, le mot « tapis » étant apparu le plus souvent à la suite de la séquence indiquée.
Ainsi, la probabilité pour que le mot pertinent soit « tapis » sera de 97 %, tandis qu’elle sera de 2 % pour « canapé », de 0,5 % pour « lit », et de 0,5 % pour l’ensemble des autres possibilités.
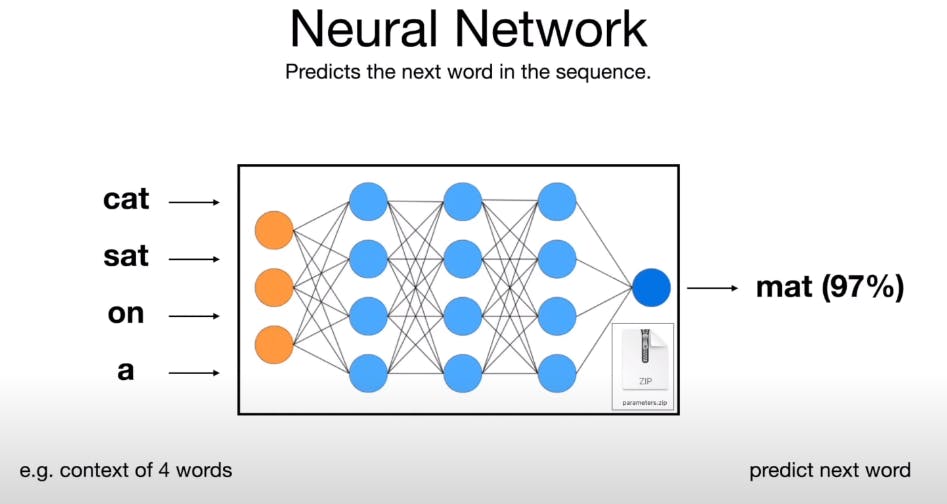
(Source : Towards AI)
Cela veut dire qu’un LLM interprète le langage humain en cherchant à contextualiser la séquence, sur la base des mots et des concepts tels qu’il les a vus regroupés des millions ou des milliards de fois. Plus on lui fournit d’informations, et plus son travail est facilité.
Le processus d’entraînement d’un LLM
Pour parvenir à ce résultat, le grand modèle de langage est « entraîné » à la façon d’un sportif de haut niveau. Un travail divisé en deux étapes majeures : le pré-entraînement et le réglage fin.
- Le pré-entraînement consiste à nourrir le modèle à l’aide d’une grande quantité d’informations (textes, images, données structurées, discours…) : plus nombreux sont les paramètres et meilleures sont ses performances. Au cours de cette phase, le LLM apprend les tâches basiques à accomplir et intègre les fonctions linguistiques fondamentales. Certains programmes peuvent être pré-entraînés sur des ensembles de données véritablement massifs, contenant jusqu’à 10 000 milliards de mots.
- Le réglage fin est l’étape d’affinage (en anglais, on parle de fine tuning). À ce stade, les capacités du grand modèle de langage sont affinées de manière à répondre à des cas d’usages particuliers, en employant des « prompts » (des instructions spécifiques). Cette phase incontournable permet de « spécialiser » le modèle en fonction de la tâche à effectuer et du domaine d’activité. Par exemple, un chatbot de relation client installé sur le site web d’une entreprise financière devra à la fois apprendre les bases conversationnelles nécessaires et intégrer le jargon technique du secteur de la finance, afin de proposer aux internautes des réponses pertinentes.
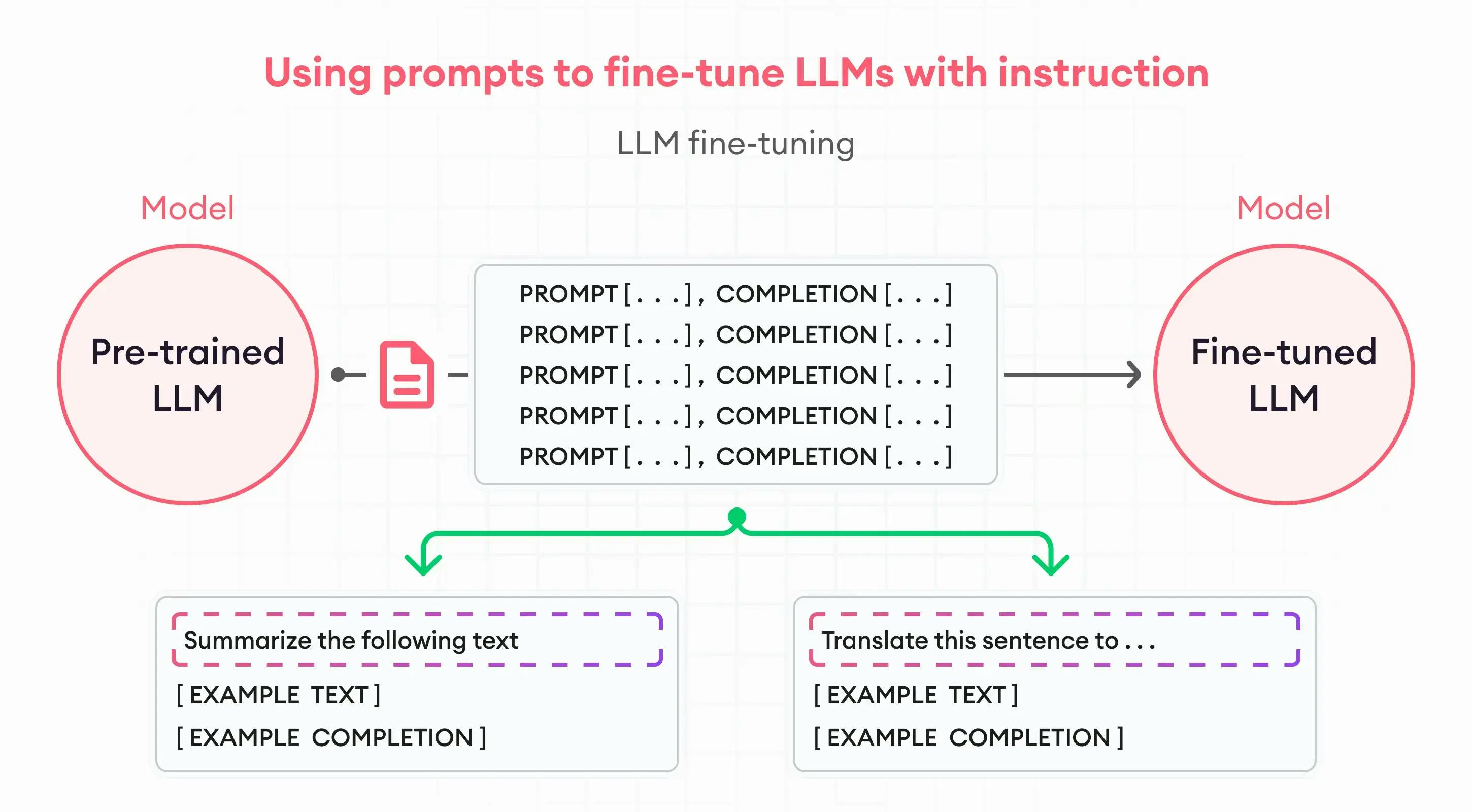
(Source : Super Annotate)
Quelles sont les limites des LLM ?
Ce fonctionnement par apprentissage sur des jeux de données massifs a aussi ses limites. Le problème principal est le suivant : un grand modèle de langage construit son référentiel à partir des informations qui lui sont fournies, qu’elles soient issues de ressources publiques (en particulier des sites web comme Wikipédia) ou de bases privées (comme celle de l’entreprise qui l’entraîne).
Or, si ces informations sont fausses, biaisées ou trompeuses, les réponses affichées par le LLM sont susceptibles de l’être tout autant.
De fait, ce programme risque d’amplifier les erreurs présentes dans les échantillons, y compris lorsque ceux-ci ont été manipulés volontairement, par exemple dans le cadre d’une campagne de désinformation.
Au-delà des erreurs commises par le programme et des fameuses « hallucinations » (ces fausses informations données aux utilisateurs lorsque le LLM n’est pas capable de fournir une réponse précise), ce biais pose un problème majeur de sécurité.
Des experts ont ainsi réussi à insérer dans des pages web des prompts invisibles aux internautes, mais adressés aux IA génératives, afin de leur faire exécuter des tâches frauduleuses – comme de leur fournir des données personnelles d’utilisateurs.
Ce type de manipulation est malheureusement assez facile à effectuer. De façon plus pragmatique, les modèles alimentés avec des informations sensibles représentent des risques en matière de confidentialité, car des invites subtiles permettent à des tiers malintentionnés de pousser le programme à les afficher.
De plus, le développement et la configuration d’un grand modèle de langage nécessitent de mobiliser d’importantes ressources en termes de personnel, d’investissements financiers, et de temps.
En particulier, il est indispensable d’étiqueter les données avant de les présenter au modèle : un travail fourni par des mains humaines (de nombreuses entreprises ont éclos sur ce nouveau marché).
LLM : quelles applications concrètes pour les entreprises ?
Terminons avec une question qui vous intéresse sans doute directement : dans quelle mesure un grand modèle de langage peut-il être employé par une entreprise lambda (qui ne cherche pas à lancer un chatbot intelligent dans le monde entier) ?
Voici quelques exemples d’applications pertinentes à plus petite échelle :
- L’automatisation des processus métiers, notamment pour la génération de texte, la classification, la prédiction ou le support client. Cela permet de réduire le temps consacré par les équipes à des tâches rébarbatives, tout en limitant les coûts associés.
- La génération de contenus textuels, comme des articles de blog, des fiches produits ou des supports pour le marketing. Même s’il n’existe pas de grand modèle de langage parfait dans ce domaine, les contenus produits par l’IA sont suffisamment qualitatifs pour répondre à des besoins basiques. Attention, toutefois, à ne pas recourir à cette solution pour créer massivement des contenus optimisés et espérer tromper les algorithmes des moteurs de recherche : ceux-ci disposent d’outils de contrôle et sanctionnent les contrevenants.
- La personnalisation des relations avec les prospects, les clients et les partenaires : l’utilisation d’un grand modèle de langage, notamment sous la forme d’un chatbot, contribue à améliorer l’expérience utilisateur et la satisfaction client via un service disponible 24h sur 24 et 7 jours sur 7, avec des réponses proches des besoins des interlocuteurs.
- La traduction : les capacités exceptionnelles des LLM en matière de traduction de contenu aident les entreprises à étendre leur portée auprès d’un plus large public, et à s’engager sur des marchés étrangers inaccessibles jusque-là.
- L’analyse et l’interprétation des données : le traitement du langage naturel transforme les processus d’analyse des informations en les rendant plus accessibles, y compris au personnel non spécialisé. La simplification des requêtes complexes contribue à la démocratisation des informations dans une démarche Smart Data, et facilite l’exploitation des données à tous les échelons de l’organisation.
Qu’est-ce qu’un grand modèle de langage ? Un programme informatique dopé à l’IA qui a le potentiel pour changer le monde.
Il y a fort à parier que, dans un avenir proche, les LLM seront véritablement partout, dans nos applications de travail comme dans nos outils du quotidien… tout en restant complètement invisibles !
Suivre le podcast
S’abonner au podcast
Recevez mes derniers podcasts directement dans votre boîte mail.